HiCache System Design and Optimization#
This document provides a comprehensive overview of SGLang HiCache, covering its system architecture, workflow and key components. It also details configuration parameters, optimization techniques, and integration with various L3 storage backends, serving as a complete reference for users and developers to understand and tune HiCache for efficient LLM inference.
Why and What is HiCache?#
In large language model inference, the prefill phase is often time-consuming: input sequences need to be first converted into Key-Value cache (KV cache) for subsequent decoding. When multiple requests share the same prefix, the KV cache for that prefix is identical. By caching and reusing these shared KV caches, redundant computation can be avoided. To address this, SGLang introduced RadixAttention, which leverages idle GPU memory to cache and reuse prefix KV caches, and HiCache, which extends this idea to host memory and distributed storage.
Inspired by the classic three-level cache design of modern CPUs, HiCache organizes GPU memory as L1, host memory as L2, and distributed storage as L3. This hierarchy enables HiCache to fully exploit the “idle” storage space of GPUs and CPUs, while integrating distributed cache systems such as Mooncake, 3FS, NIXL, and AIBrix KVCache for global KV cache storage and scheduling. As a result, HiCache significantly expands KV cache capacity while maintaining strong read performance—especially in workloads such as multi-QA and long-context inference, where KV cache reuse is frequent. For detailed benchmark results, see this blog.
System Design#
Overall Architecture#
In many modern CPU architectures, the small but fast L1 and L2 caches are private to each core, enabling rapid access to the hottest data, while the larger L3 cache is shared across all cores to significantly reduce redundancy within the cache. Similarly, in HiCache, the L1 and L2 KV caches are private to each inference instance, whereas the L3 KV cache is shared among all inference instances within the cluster.
HiRadixTree: Metadata Organization in HiCache#
For KV cache data organization, HiCache builds upon the RadixTree structure introduced in RadixAttention and proposes HiRadixTree. In RadixAttention, each node of the RadixTree corresponds to the KV cache of a consecutive span of tokens in GPU memory. A path from the root to a leaf node represents the prefix of a request, and shared prefixes across multiple requests can reuse the same nodes, thereby avoiding redundant storage.
HiRadixTree extends this idea: each node corresponds to the KV cache of a span of consecutive tokens and records where that KV cache is stored—whether in local GPU memory, CPU memory, L3 storage, or multiple of these tiers. If stored locally, HiRadixTree maintains precise metadata, including the exact storage address. However, to reduce overhead, HiRadixTree does not store or continuously synchronize metadata for L3 KV cache. Instead, when accessing L3 data, it queries the backend in real time to retrieve the necessary metadata, such as whether the data exists and on which server and location it resides.
Overall Workflow#
The workflow of HiCache mainly involves three key operations: local match, prefetch and write-back. When the system receives a new request, it first searches the local L1 and L2 caches for matching KV caches. For parts not found locally, it attempts to prefetch from L3. After prefetching, all required KV caches are loaded into the GPU for computation. Once the prefill computation is complete, the system considers storing the newly generated data into L2 or L3.
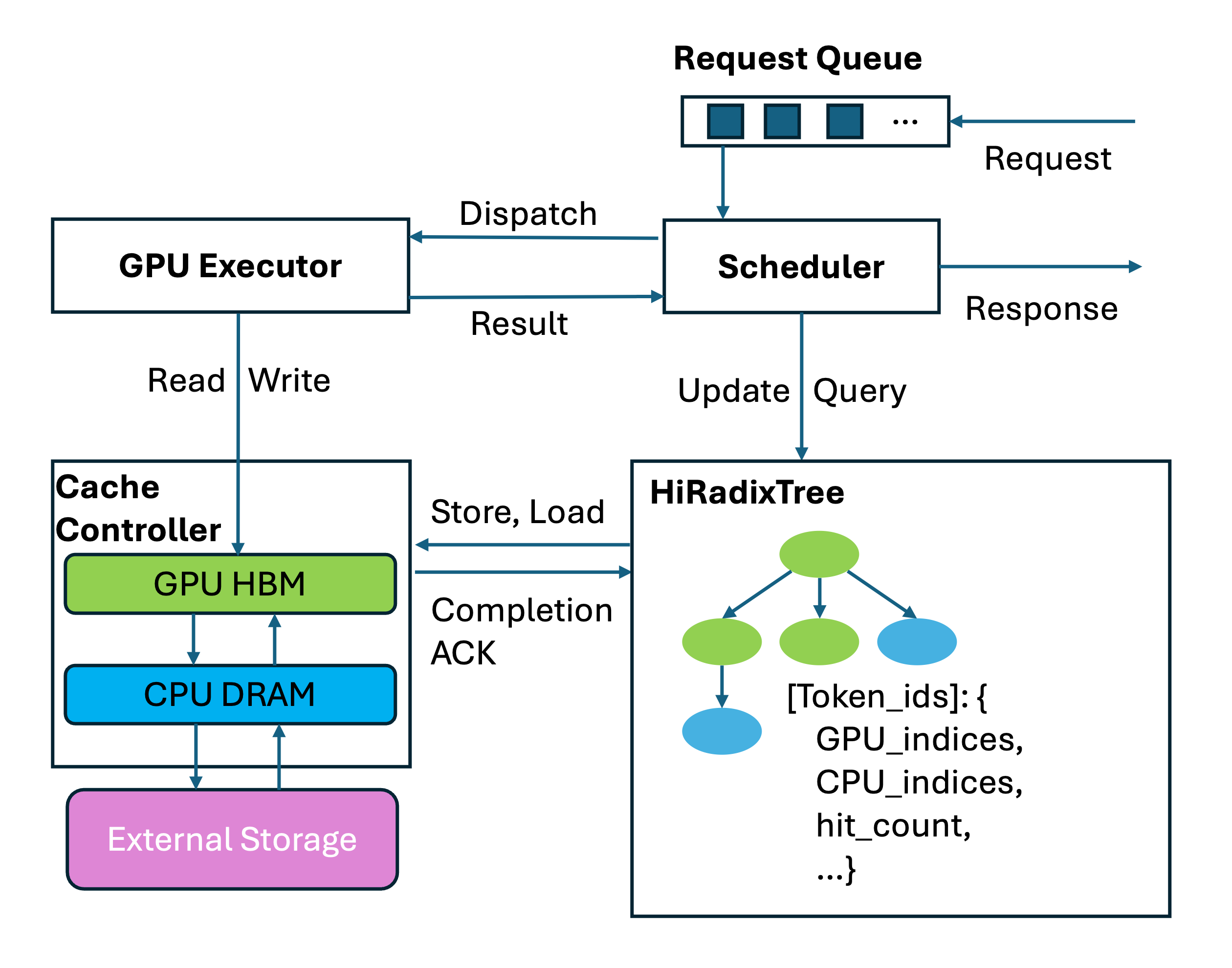
Local Match#
Local matching is the first step in HiCache’s workflow, where incoming request tokens are matched against the HiRadixTree to locate cached KV data in local memory tiers (L1 GPU memory and L2 host memory).
The matching algorithm traverses the HiRadixTree from the root node, following child nodes that match the token sequence prefix. At each node, the incoming token sequence is compared with the node’s stored token sequence. When page_size > 1, matching is performed at the page granularity to optimize memory access patterns. If a match terminates within a node’s stored sequence, the node is automatically split to create an exact boundary, improving the efficiency of future matches.
The algorithm returns a continuous prefix of the request, with the first part residing in L1 and the latter part in L2.
Since the process only requires traversing the local HiRadixTree and does not involve any actual data copying, local matching is extremely fast.
Prefetch from L3#
Data prefetching is one of HiCache’s core optimization techniques, designed to proactively load KV caches from L3 storage into local L2 memory, thereby reducing access latency during subsequent operations.
Prefetch Trigger Conditions: After local matching, for the parts not found in L1 or L2, the system queries L3 to retrieve metadata for the next continuous matching KV caches. If the length of hit cache in L3 exceeds a threshold (default: 256 tokens, configurable), a prefetch operation is triggered.
Prefetch Strategies: HiCache provides three different prefetch termination strategies to address different scenario needs:
best_effort: Terminates immediately when GPU can execute prefill computation, with no waiting time, suitable for scenarios extremely sensitive to latency.
wait_complete: Must wait for all prefetch operations to complete, suitable for scenarios requiring high cache hit rates.
timeout: Terminates after specified time or when complete, balancing latency and cache hit rate needs.
After prefetching stops, the data already fetched is used together with the local data for the prefill computation.
For timeout strategy, HiCache introduces two configuration parameters to support fine-grained control over prefetch timeout conditions:
prefetch_timeout_base: the base timeout, representing overhead unrelated to the number of tokens (e.g., scheduling and synchronization).prefetch_timeout_per_ki_token: the incremental timeout per thousand tokens.
The timeout is computed as:
timeout = prefetch_timeout_base + prefetch_timeout_per_ki_token * num_token_to_fetch / 1024
Data Write-back#
The write-back mechanism is responsible for moving frequently accessed KV caches from L1 to L2 and L3, enabling larger and longer-term storage as well as cache sharing across instances.
Configurable Write-back Policies: HiCache supports three write-back strategies:
write_through: Every access is immediately written back to the next level. When bandwidth is sufficient, this strategy provides the strongest caching benefit.
write_through_selective: Data is written back only after the access frequency exceeds a threshold. This strategy backs up only hot data, reducing I/O overhead.
write_back: Data is written back to the next level only when it is evicted from the upper level. This strategy alleviates storage pressure and is suitable for scenarios where storage capacity is limited but memory utilization must be maximized.
Cross-instance Sharing: When data is written back from L2 to L3, only data not already present in L3 is transferred. KV caches stored in L3 can then be shared across all SGLang instances in the cluster (depending on the L3 backend implementation), significantly improving cache hit rates within the same memory budget.
Multi-Rank Synchronization#
During multi-GPU parallel computation, such as tensor parallelism (TP), HiCache must ensure consistent states across different ranks. Therefore, critical computation steps require the use of all_reduce for state synchronization.
For example, during prefetching, all_reduce(op=min) is used to ensure that all ranks obtain the same number of L3 hits, preventing inconsistent judgments about whether the prefetch threshold has been reached. Similarly, after prefetching completes or terminates, all_reduce(op=min) is again required to guarantee consensus among ranks on the prefix length of the successfully retrieved KV cache.
Data Transfer Optimization#
Zero-Copy Data Transfers: Both prefetching and write-back involve substantial data movement. Minimizing the number of data copies can significantly improve system performance. HiCache supports passing memory addresses and sizes directly when transferring data from L2 memory to an L3 backend.
“Batch-Oriented” Data Organization: The granularity of data reads and writes has a major impact on performance. To address this, HiCache L3 stores and transfers KV cache data at the granularity of pages and supports different data layouts beyond the existing layer first scheme, including page first and page first direct. Under the page first and page first direct layouts, all KV cache data belonging to the same page is placed in contiguous memory, allowing it to be passed as a single object to L3 using zero-copy transfers.
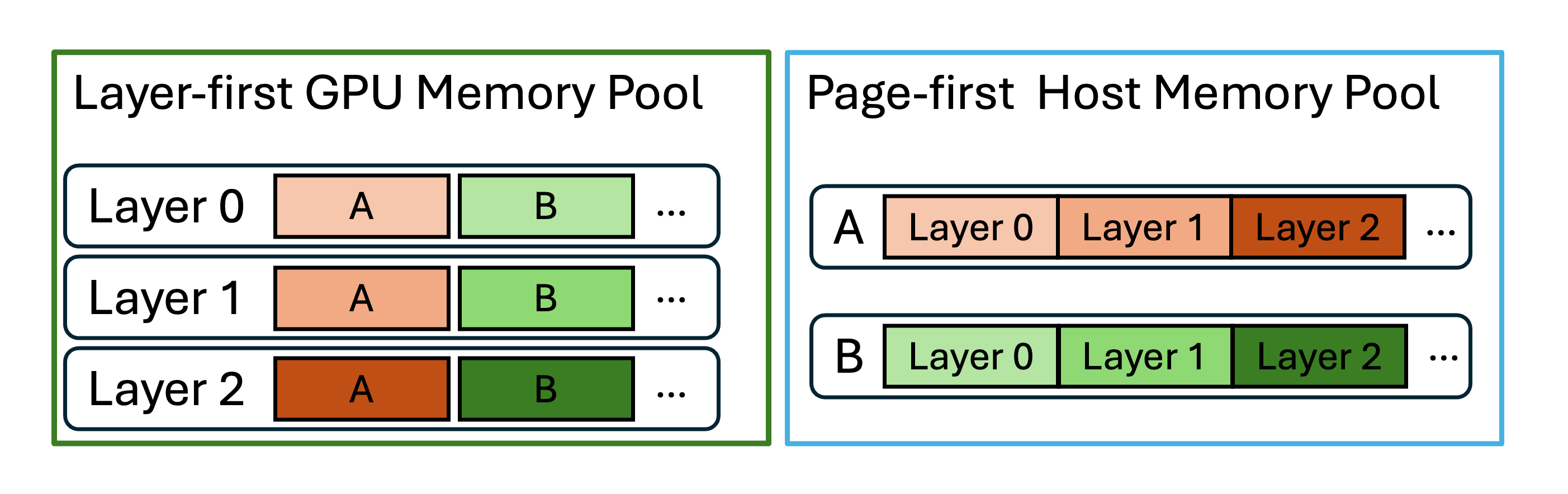
However, because GPU KV computation is naturally performed layer by layer, the GPU inherently operates in a layer first layout. When transferring page first data from L2 to the GPU, data must be transferred at the granularity of one token per layer. The page first direct layout mitigates this issue by grouping together all tokens of a given layer within a page, allowing transfers from L2 to GPU to be aggregated at the page-layer level.
CPU-to-GPU Transfer Optimizations: In HiCache, moving data from CPU memory to GPU is as performance-critical as prefetching data from L3 to L2. HiCache employs several optimizations for this process:
Compute-Transfer Overlap: During the prefill phase, when transferring data from CPU to GPU, HiCache overlaps layers by concurrently loading the KV cache of layer N+1 while computing layer N. This effectively hides data transfer latency.
GPU-assisted I/O Kernels: On top of
cudaMemcpyAsync, HiCache implements a set of GPU-assisted I/O kernels specifically optimized for KV cache transfers between CPU and GPU. Compared to the baseline approach, these kernels achieve up to 3x higher transfer speed.
Write-back Optimization for MLA: For MHA (Multi-Head Attention) models under multi-TP, each rank holds 1/tp_size of a token’s KV data. In contrast, for MLA (Multi-Layer Attention) models, all ranks hold the complete and identical KV data for each token. HiCache includes a dedicated optimization for MLA: only one rank initiates the write-back operation, ensuring that data is not redundantly stored across ranks.
Integration with PD-Disaggregation Deployment Mode#
SGLang supports a PD (Prefill-Decode) disaggregation deployment mode through the Mooncake TransferEngine (for details, see this doc). In the PD-disaggregation deployment mode, HiCache can be enabled on both the prefill nodes and decode nodes to optimize prefill performance. If enabled on decode nodes, the decode output will also be written back to L3.
Unified Interfaces and Rich L3 Storage Backends#
HiCache encapsulates all read, write, and query operations on L3 backends within the class HiCacheStorage(ABC), exposing a set of simple and consistent interfaces. This design supports a wide range of L3 storage backends and allows users to select the one that best fits their specific use cases.
Mooncake: Mooncake is a high-performance caching system for LLM inference that leverages RDMA and multi-NIC resources to enable zero-copy, ultra-fast data transfers. Try Mooncake here.
DeepSeek 3FS (HF3FS): HF3FS is a Kubernetes-native distributed storage solution with operator-based deployment. Try HF3FS here.
NIXL: NIXL provides a unified API for accessing various storage plugins, including but not limited to DeepSeek’s 3FS, GPU Direct Storage (GDS) and Amazon S3-compatible object storage. Try NIXL here.
AIBrix KVCache: AIBrix KVCache is a production-ready KVCache Offloading Framework, which enables efficient memory tiering and low-overhead cross-engine reuse. Try AIBrix KVCache here.
HiCacheFile: A simple file-based storage backend for demonstration purposes.
Specifically, LMCache, an efficient KV cache layer for enterprise-scale LLM inference, provides an alternative solution to HiCache. Try LMCache here.